Market Summary
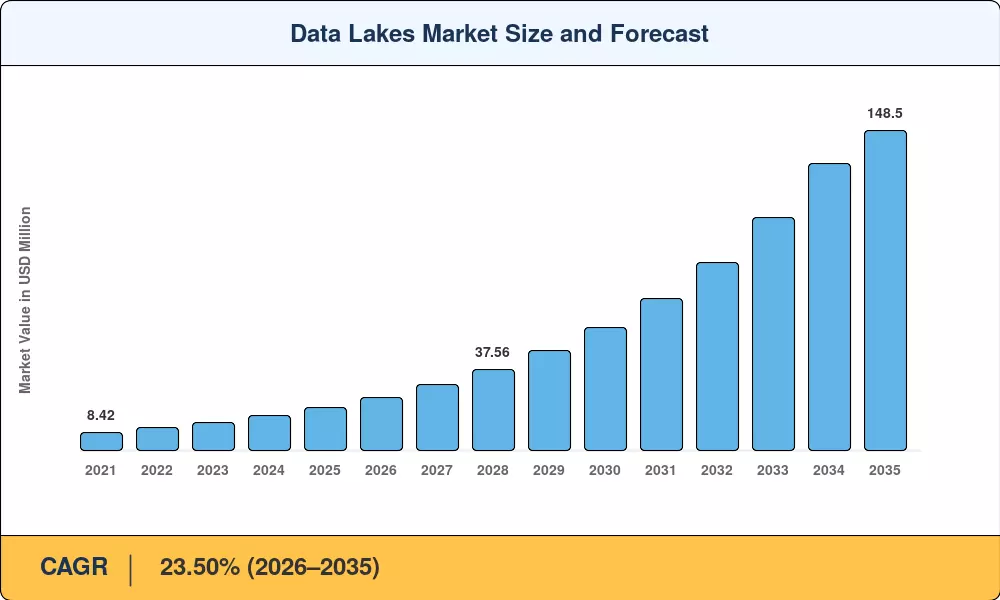
The Data Lakes Market reached an estimated USD 20.18 billion in 2025 and is projected to climb to USD 24.62 billion in 2026 before surging to USD 148.50 billion by 2035, registering a CAGR of 23.50% over the 2026–2035 forecast window. This trajectory is propelled by an explosion in unstructured data volumes — accelerated by generative-AI training pipelines — and by tightening regulatory record-keeping mandates such as the EU Data Act and SEC climate-disclosure rules that compel enterprises to retain, catalog, and audit vast data repositories at scale.
A sweeping technology transformation is reshaping how organizations store and analyze information. Legacy siloed data warehouses and on-premises Hadoop clusters are giving way to cloud data lake architecture with Delta Lake and open-table formats like Apache Iceberg that unify batch and streaming workloads on a single storage layer. The data lakehouse for unified analytics paradigm has drawn more than USD 9 billion in cumulative venture funding since 2022, as Fortune 500 firms report 30–38% total-cost-of-ownership savings by collapsing separate lake and warehouse footprints into one governed tier [3].
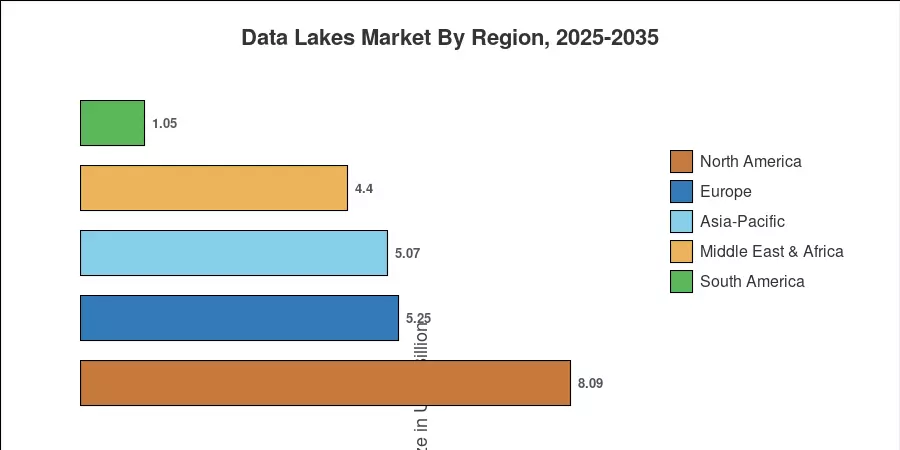
North America commands a leading 40.10% share of the Data Lakes Market, underpinned by hyperscaler headquarters and mature cloud adoption curves. Asia-Pacific is the fastest-growing region at a 25.10% CAGR, fueled by India's Digital Public Infrastructure push and China's national data-exchange platforms. Europe secures the second-largest share at roughly 26%, driven by GDPR-adjacent data-sovereignty requirements that favor on-continent data lake deployments. As real-time data ingestion into data lakes becomes table-stakes for AI-driven decision-making, the market's growth runway extends well into the next decade[6].
Key Report Takeaways
• By Offering
- Solutions captured roughly 73% of revenue in the Data Lakes Market in 2025, reflecting strong demand for integrated platforms supporting Apache Spark processing for data lake analytics
- Services are poised to expand at a 26.40% CAGR through 2035 as enterprises seek managed deployment and data lake governance and access control consulting
• By Deployment
- Cloud deployment held the majority share of the Data Lakes Market in 2025, valued at approximately USD 13.70 billion
- Hybrid and multi-cloud architectures are forecast to grow at a 24.60% CAGR to 2035 as organizations pursue multi-cloud portability strategies
• By Region
- North America dominated the Data Lakes Market with a 40.10% share in 2025
- Asia-Pacific is set to accelerate at a 25.10% CAGR through 2035, driven by cloud-first government digitization programs
MRFR's market-size estimates combine bottom-up revenue analysis from vendor filings with top-down macroeconomic modeling. Historical data (2021–2024) reflects reported revenues, while forecast years apply the calibrated 23.50% CAGR with adjustments for anticipated regulatory and technology catalysts.










.webp?v=1780562970)